
From Pipelines to Prompts: My Journey Exploring LLMs and Data Access
After the initial frenzy around large language models — the excitement, the demos, the explosion of tools and frameworks — I took a step back. I wanted to understand something deeper: how these models actually interact with data. Not just in a theoretical sense, but practically, from a data engineer's point of view.
I’ve spent years building systems to move, transform, and expose data at scale. So naturally, the question that caught my attention was: how can LLMs access that data meaningfully? And just as important — how does the quality and structure of our data shape the quality of LLM outputs?
This isn’t meant to be a deeply technical post. Think of it more as a field journal — a snapshot of what I’ve been learning as I explore how LLMs and data engineering come together. I’ll touch on the assumptions I had, what surprised me, and what I’m still figuring out.
So, where does data engineering even meet LLMs?
At first glance, the connection might not be obvious. Data engineers are usually knee-deep in pipelines, warehouses, ETL jobs, and dashboards. But as I looked closer, I realized the overlap is real — and growing.
Even within well-structured data environments, making sense of hundreds of tables — from raw ingested data to the refined layers consumed by BI or machine learning teams — can be overwhelming. And that's just the schema. You also have to understand lineage, freshness, and logic baked into transformation steps.
So I started wondering: could LLMs help answer questions like “What does this table represent?” or “When was this data last updated?” or even “Given this user profile, what product should we recommend?”
Those felt like very real, very practical use cases. But of course, the next question was: how do you give an LLM access to all that?
My first thought? Let’s train it.
Naturally, I thought the solution was to train a model using my organization’s data. That idea didn’t last long.
Turns out, training a custom LLM is out of reach for most teams. Not just because of cost — though that’s a big part of it — but also due to the sheer complexity. It requires massive datasets, specialized infrastructure, and a team of ML experts. And even if you pull that off, your model still won’t have access to constantly updating, real-time data unless you retrain it regularly.
Fine-tuning seemed like a more accessible path. It’s a way to adapt existing models to your use case by adjusting their weights using examples specific to your domain. In practice, though, it still demands a solid dataset of well-labeled questions and answers. And even then, it doesn't solve the "live data" problem. Plus, there's no guarantee the model’s responses will stay grounded or accurate.
That��’s when I stumbled across a different approach: RAG — Retrieval-Augmented Generation.
Retrieval-Augmented Generation: the missing piece
RAG isn’t new. Patrick Lewis introduced the term back in 2020, but it's gained traction recently as a practical solution for improving LLM responses without retraining the model itself.
The idea is pretty simple: when a user asks a question, the system retrieves relevant data and includes it in the prompt sent to the model. That context gives the LLM the information it needs to generate a more accurate and relevant answer.
Let’s say someone asks, “What are the rules for a borrower with low credit getting a mortgage from Lender X?” With RAG, instead of hoping the model knows the answer, the system fetches Lender X’s policy from your knowledge base and includes it with the question.
But of course, it’s not just about looking up keywords. You need semantic understanding. If the question says “home” and the policy document uses “house” or “condo,” you still want a match.
That’s where embeddings come in — they transform text into high-dimensional vectors, allowing the system to search for similarity in meaning, not just phrasing.

Embeddings: meaning through math
Embeddings opened up a new layer of understanding for me. I started experimenting with OpenAI’s text-embedding-3-large, which supports up to 8192 tokens and creates vectors with 3072 dimensions.
Through trial and error, I noticed how shorter pieces of text create very focused vectors, which can be great for pinpoint matches — but they often lack broader context. On the other hand, longer chunks bring in more nuance and richness, but they can get noisy, and sometimes dilute the core message.
It’s a balancing act. And it made me realize: building a high-quality knowledge base for RAG isn’t just about storing documents. It’s about splitting them strategically, optimizing embedding inputs, and designing for relevance — not just recall.
That’s a topic I’ll definitely dive deeper into in another post.
Live data changes everything
While RAG solves a big part of the puzzle, it doesn’t help when users need live or frequently updated information — something like “when was this table last refreshed?”
To handle that, I started exploring MCP — the Model–Context–Protocol. It lets the model pause its reasoning process and request external data from pre-defined tools or APIs before continuing the response.
This was a game changer. Suddenly, the model could call out to our systems to fetch things like table metadata, recent pipeline runs, or even external API results. It’s not always seamless, and the orchestration requires work — but the fact that it’s possible at all is impressive.
I’ll definitely write more about implementing MCP in production, but even at this early stage, it’s opened up new possibilities.
The prompt problem
With all these tools in place — embeddings, RAG, live data through MCP — I thought I had most of the pieces.
But then I hit another wall.
How do you craft a single system prompt that covers every kind of user question, from data lineage to business logic to schema exploration? At first, I tried to cram everything into one big prompt — background, examples, instructions, all of it.
It didn’t scale. Even with newer models that accept 100k+ tokens, performance dropped. The models got confused or ignored parts of the context. And besides, running massive prompts gets expensive.
Eventually, I learned the importance of focused prompts and targeted instructions. That’s where LangChain and LangGraph came in.
They helped me build agents with specialized roles and orchestration logic to route questions to the right place. I could finally structure flows that allowed recursion, conditional steps, and long-running processes — all in a way that felt natural.
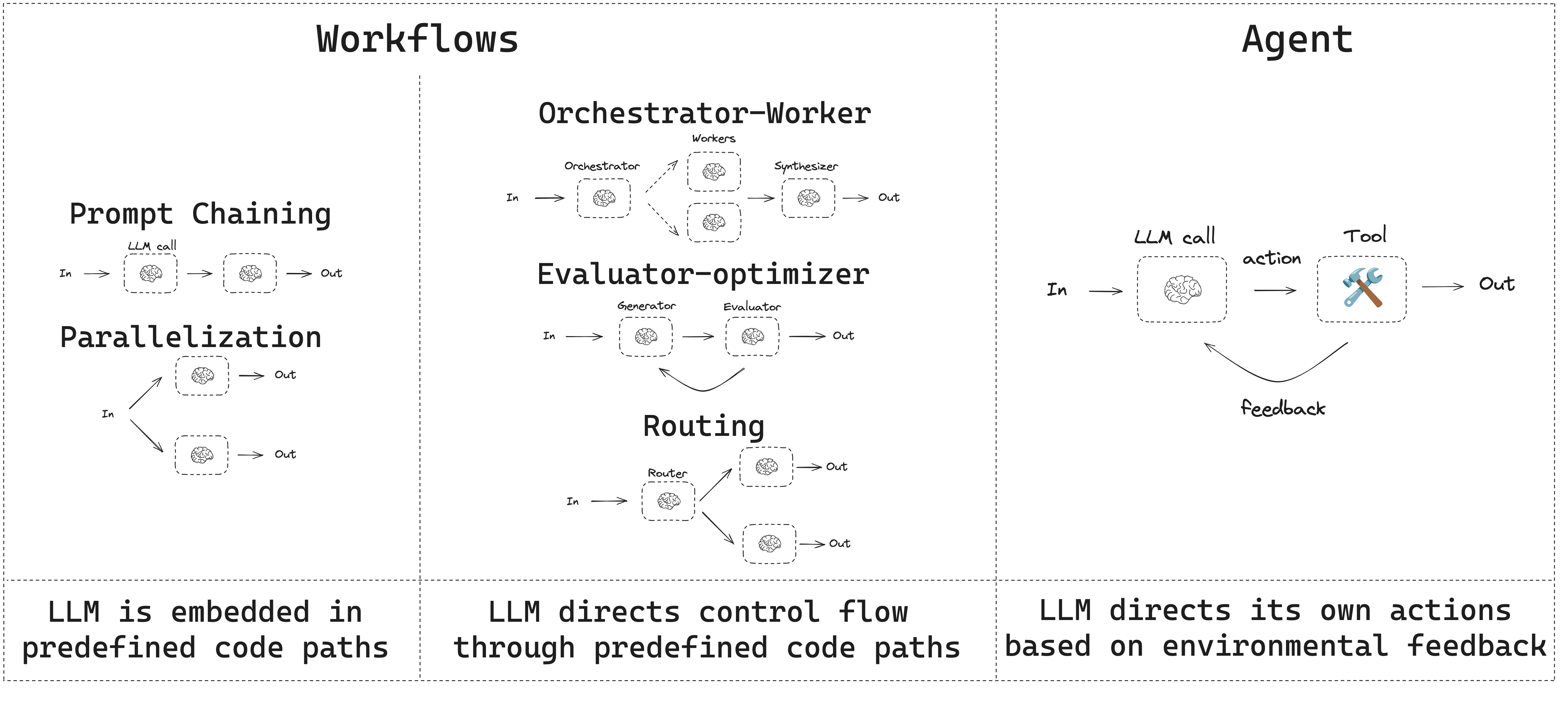
source: langchain-ai.github.io/langgraph/tutorials/workflows
Honestly, this solved a lot more than I expected. Even complex, multi-step queries became manageable. And the modular setup made the system much easier to debug and extend.
What’s next?
I think the current toolset — RAG, embeddings, MCP, agent orchestration — works surprisingly well. But it’s not perfect.
Models still make mistakes. They still sometimes say too much or not enough. And in data workflows, an incomplete answer can be just as dangerous as a wrong one.
Right now, I’m diving deeper into how context is prepared and retrieved — tweaking embedding dimensions, experimenting with chunking strategies, evaluating retrieval performance — all with one goal in mind: helping the model give the right answer, every time.
That’s the next leg of this journey, and I’ll be sharing what I learn along the way.