
Effective Practices for Managing dbt Failures in Prod Environments
In this post, we'll discuss considerations for utilizing dbt in production environments, specifically addressing scenarios where clients rely on data from leaf and intermediate models in the event of a failure. This post assumes a basic familiarity with dbt and hands-on experience with running it in production. Even if you are just starting and contemplating migrating from the old ETL to dbt, the information here may prove valuable.
The design of dbt is rooted in software engineering principles and the foremost among them is the acknowledgment that things will break. Regardless of the quality of your models and the efficiency of the engine running them, failures are inevitable.
The "Oh, no! The pipeline is broken" moment
Consider the following DAG extracted from a dbt labs' presentation. Let's say, this part of the pipeline takes ~4 hours to complete. I know, your whole pipeline takes only ~30min to build but mine is not as optimized as yours.
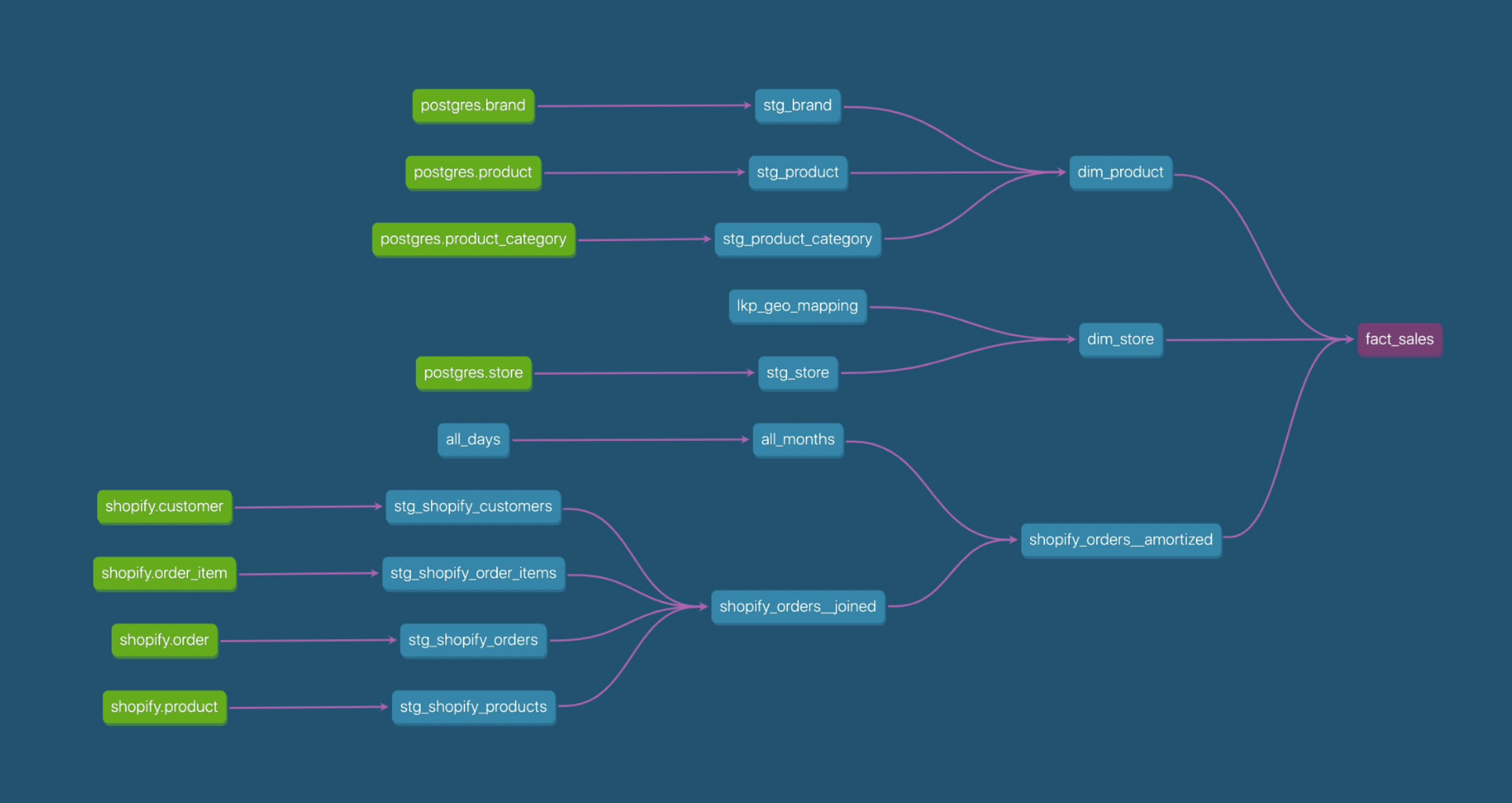
The fact_sales table is mainly used by Sales and Account teams. On the other hand, the Marketing team relies on dim_store and shopify_orders_joined to define strategies for current and new campaigns based on store locations and the volume of sales on those.
"What about the failure??"
Bare with me, we will get there before my pipeline completes!
A naive approach to running the pipeline would be basically a matter of
$ dbt run
I'm sure that happens only with me, but let's say a bad JOIN was introduced on shopify_orders_joined , now all orders and items are duplicated. The data engineering team will notice that only when Account folks are complaining the numbers don't add up. The Data Engineer who had to fix the issue late at night because of the balance deadline decided to add tests. Installed the dbt-utils package and added unique and not_null whenever he could. Now, the dbt runs using the following:
$ dbt build --fail-fast
Now, tests are executed right after a model is built and on a failure, all other running models are immediately cancelled. Awesome!
Well, Do you remember that the pipeline takes a few hours to complete? Let's say dim_store succeeded but shopify_orders_joined failed. Differently from other teams, Marketing uses the data live. Their applications and strategies constantly rely on those tables to dynamically update prices. I even think this could be a DAG from a website we use for booking vacations...
Back to the case. Now, teams have a mix of updated data, outdated data, and wrong data available to them. The marketing team doesn't have reliable data and can't operate. The company is losing money every minute on the busiest hours of the year. Ops, the DAG takes 4 hours to complete after the problem is found and fixed.
Data, you got a promotion!
Based on those events, the Data Engineer decided the pipeline was going to be built in a separate environment and used to atomically replace production data only after the build was complete and all tests succeeded. Now the data is promoted to production only when it is ready for it.
That's perfect! There is no mix between old and new data while the pipeline is running. Instant new data on the production environment, and the most important one: production data is complete, tested, and verified.
"How do we do that with dbt?"
Well, dbt doesn't have that feature out-of-the-box but we can use the tools provided. For this example, I'll consider all models are built in only one schema/dataset/DB for simplicity. Likely most pipelines will spread through several schemas/datasets.
The profiles.yml file allows us to define multiple target schemas and database configurations. We will use profiles to build on a custom schema and then another one when moving data into production. The example below is using Snowflake as the Warehouse solution.
profiles.yml
default: target: build_run outputs: build_run: type: snowflake account: jaffle user: dbt database: prod schema: dbt_pre prod: type: snowflake account: jaffle user: dbt database: prod schema: promoted
Building the data using the build_run target will make all data flow into the dbt_pre schema. Although moving the data into the promoted schema doesn't require dbt, it's important to still use it as the artifact files created have references to data in the dbt_pre schema, which may contain incomplete and wrong data. We can create a macro to rename the schema using the prod target and build the catalogue again. The macro would look like:
promote.sql
{% macro promote %} {% set sql %} CREATE OR REPLACE SCHEMA PROMOTED CLONE DBT_PRE {% endset %} {% endmacro %}
... and the dbt command would look like this:
$ dbt run-operation promote --target prod $ dbt compile --target prod
Now, data would land on the correct production schema and artifacts are storing references to them. Data is atomically updated in production and only after the build and tests are complete and passing.